
Have you ever noticed how SharePoint does not reload the entire web page when navigating between SharePoint pages? It’s called partial page navigation. When working with SharePoint Framework (SPFx), you need to take this into account. Your SPFx code might break on this just like your tongue may break on this blog post title!
What is partial page navigation?
In the early days of the interwebs, when navigating to a new page, a website would typically reload the entire page. This includes all HTML, CSS, and JavaScript files. This could be slow, especially on slower connections. Many browsers cache static resources, but even then, reloading a page makes websites flash while they are rerendering the page. Many websites have implemented techniques since to optimize this experience, especially using JavaScript frameworks like React or Angular, which made the user experience faster and more fluent.
SharePoint does this as well. The feature is called ‘partial page navigation’ and it is a technique that SharePoint uses to optimize the user experience. When you navigate between pages in SharePoint, it not always reloads the entire page. Instead, only the necessary resources are loaded client-side. This makes the navigation faster and more seamless. It behaves a little like a single page application (an SPA), even if it isn’t one.
You can see an example below, where I edited the site title HTML-element through the browser dev tools. A change that does not persist across redirects. You can clearly see it stays the same across different pages, right until I click back to the home page.
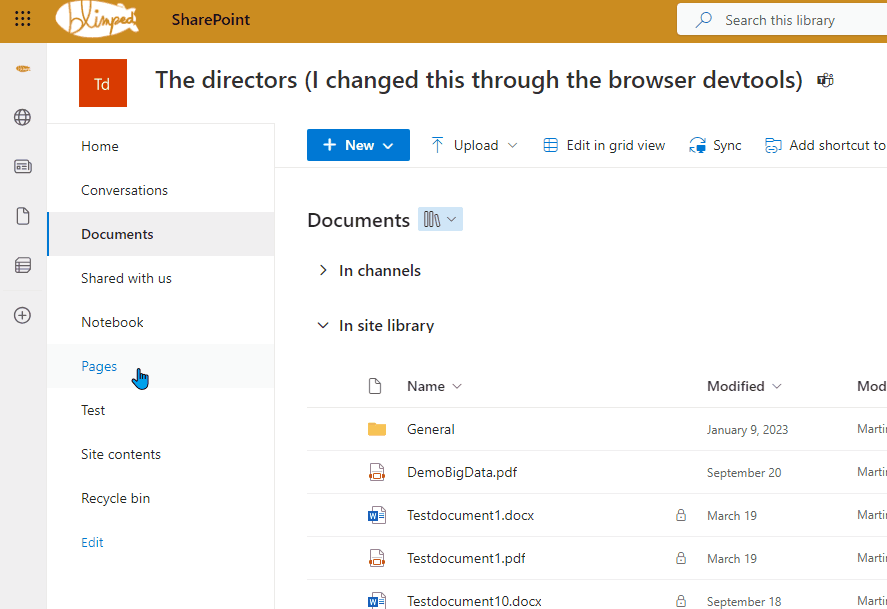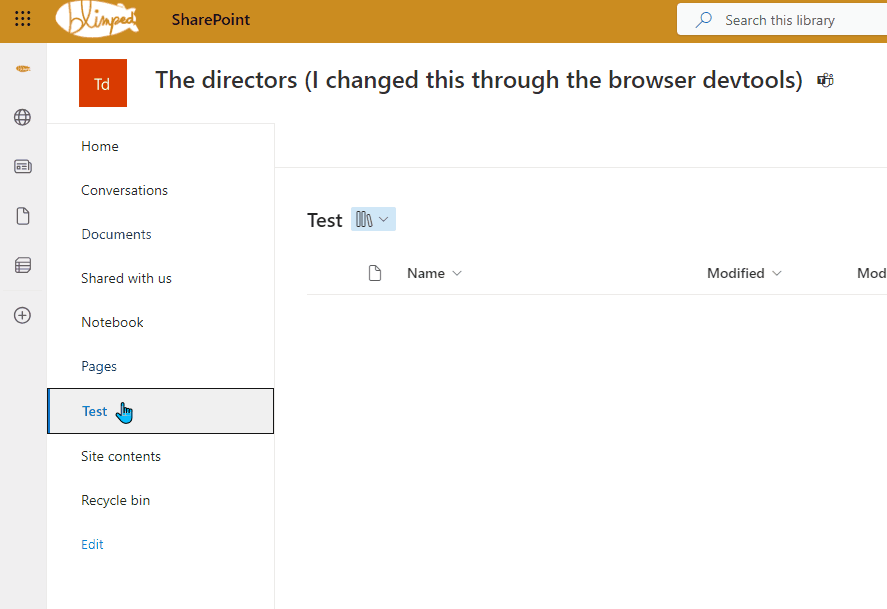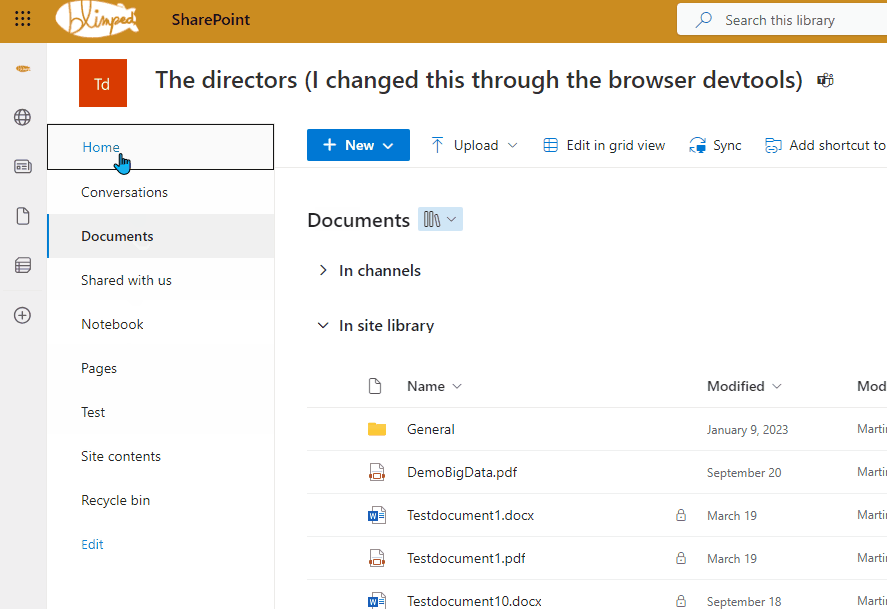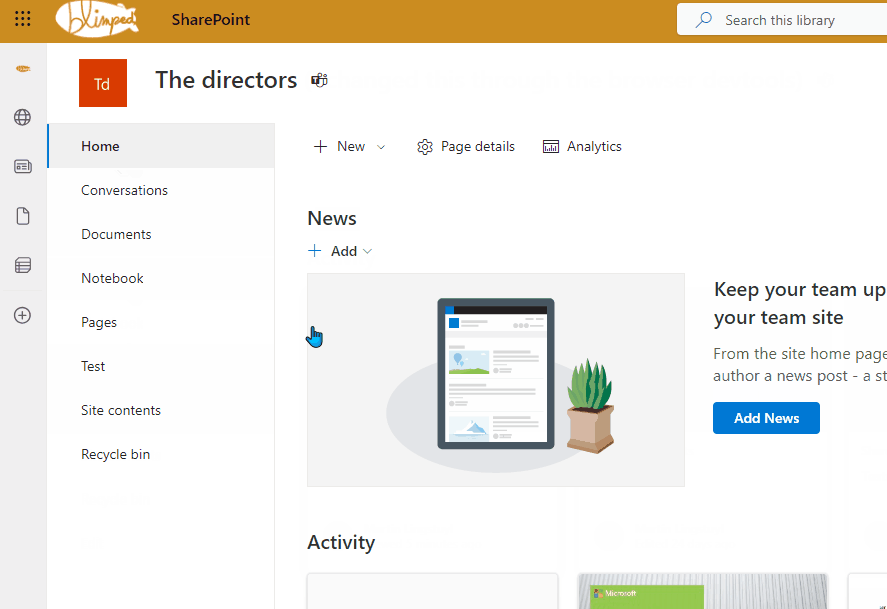
And even when the title changes back, that’s not even because the page actually fully reloaded. It’s SharePoint reloading the title section through JavaScript.
So what does this have to do with SPFx?
SPFx is basically JavaScript executing in the browser. Now in the pre-SPA days, JavaScript was often supplementary, and issues with your JavaScript code would often not have far reaching impact, because the JavaScript process was limited to the lifetime of the page. As soon as people clicked a link, the browser would load that new page and completely restart the JavaScript process.
But SPA’s have their own new challenges, because the code keeps on running. A little issue may break a lot. A similar thing occurs with SharePoint! When a SharePoint page does not reload entirely, that means the JavaScript processes running on that page are not refreshed either. They will keep on running. Which means we’re dependant on SharePoint to dispose of certain resources and start rendering others. Just like in the case of the site title.
Note:
When a SharePoint page does not reload entirely, that means the JavaScript processes running on that page are not refreshed either.
SPFx services and partial page navigation
An interesting example of how this can go wrong is with SPFx services created using the ServiceScope class. If you’ve never used that: it’s a great way to create services that are nicely decoupled from your components and/or extensions. It’s built on the Service Locator pattern. Let’s take as an example the following scenario.
🎬 The scenario
Say we have a SharePoint environment with multiple sites, one site per customer. Every customer site has an orders list. An SPFx webpart will load order data from this customer orders list on the current customer site and shows it in a nice list or table. I’m not saying this is a real world example. I just use it to illustrate a point. Heck, the following code might not even compile as I’m writing this on the fly. 😁
📺 The webpart
The following is a simplified example of a React component in an SPFx webpart that shows a list of orders. When the webpart is loaded, the component is rendered. The useEffect React hook is used to run code on the initial render. It consumes an SPFx service and requests a list of orders. Consuming a service in this way means that SPFx will try to find an existing instance of the service. If it does not find it, it creates a new one and returns it.
export function OrdersList(props: IOrdersListProps): JSX.Element {
const [orders, setOrders] = React.useState([]);
useEffect(() => {
const customerOrderService = props.serviceScope.consume(CustomerOrdersService.serviceKey);
customerOrderService.getOrders().then((items) => {
setItems(items);
}).catch((err) => { console.error(err); });
}, []);
return <ul>{orders.map(o => `<li>${o.OrderDate} - ${o.Title} - $ ${o.OrderAmount}</li>`)}</ul>
}
Note:
Consuming a service means that SPFx will try to find an existing instance of the service. If it does not find it, it creates a new one and returns it. It's a bit like Dependency Injection.
📡 The service
The service is basically just a class based on an interface. Just like the webpart consumed the service, the service can in its turn consume other services. It’s a little like the concept of Dependency Injection. In our case below, the service requests an SPHttpClient and PageContext after it’s finished being initialized by SPFx. It gets the current site url from the PageContext object and uses it in the getOrders method to request a list of list items from the orders list on the current site.
export class CustomerOrdersService implements ICustomerOrdersServiceService {
public static readonly serviceKey: ServiceKey<ICustomerOrdersServiceService> = ServiceKey.create<ICustomerOrdersServiceService>("SPFx:CustomerOrdersService", CustomerOrdersService);
private _customerSiteUrl: string;
private _spHttpClient: SPHttpClient;
constructor(serviceScope: ServiceScope) {
serviceScope.whenFinished(() => {
this._spHttpClient = serviceScope.consume(SPHttpClient.serviceKey);
const pageContext = serviceScope.consume(PageContext.serviceKey);
this._customerSiteUrl = pageContext.web.absoluteUrl;
});
}
public async getOrders(): Promise<IOrderListItem[]> {
const response = await this._spHttpClient.get(`${this._customerSiteUrl}/_api/web/lists/getbytitle('Orders')/items?$select=OrderDate,OrderAmount,Title`, SPHttpClient.configurations.v1);
const items = await response.json();
return items.value;
}
}
So far so good it seems. However…
💀 The above code can have dangerous side effects! 💀
🚨 The pitfall
The problem with the above code is mainly about a wrong assumption. The problem is this: the Service object can stick around longer than we assumed. We may think we get a new CustomerOrdersService instance every time the webpart is rerendered from scratch, but that’s not true. SPFx can return the existing service instance for quite a while, assuming the code is still loaded and not disposed and the user is viewing a page where the same SPFx solution is used.
The service instance can stick around across redirects to other pages, even to pages in other sites. The callback in serviceScope.whenFinished() is only called once, when the service is first created. So if the user navigates to another site, the class instance that is returned to the webpart can still have the old site url set as a property. In this case that means that once the OrdersList webpart is loaded, the service will load the orders from the wrong site!
Note:
SPFx can return the existing service instance for quite a while, assuming the code is still loaded and not disposed and the user is viewing a page where the same SPFx solution is used.
😱 Please take a moment to envision the amount of things that an go wrong because of such an issue! 😱 In the above example it leads to people viewing a wrong list of customer orders they already had access to. But depending on what the webpart does, this could also lead to data being uploaded to the wrong site, allowing other people to see things that they shouldn’t, which constitutes the definition of a data leak!
And just like that, a simple webpart with an upload form could theoretically turn into a security jump scare.
🩹 The fix
So how can we fix the above issue? What we can do in this instance is set the entire PageContext to a class property, instead of just the site url:
private _pageContext: PageContext;
private _spHttpClient: SPHttpClient;
constructor(serviceScope: ServiceScope) {
serviceScope.whenFinished(() => {
this._spHttpClient = serviceScope.consume(SPHttpClient.serviceKey);
this._pageContext = serviceScope.consume(PageContext.serviceKey);
});
}
serviceScope.whenFinished() is still only called once, but the PageContext object is a reference type. It’s a reference to an object in memory. When the user ends up on another page or site, SPFx will update the PageContext object with the new information. In the getOrders method, we can now safely use the _pageContext object to get the current site url:
public async getOrders(): Promise<IOrderListItem[]> {
const response = await this._spHttpClient.get(`${this._pageContext.web.absoluteUrl_}/_api/web/lists/getbytitle('Orders')/items?$select=OrderDate,OrderAmount,Title`, SPHttpClient.configurations.v1);
// etc...
}
Conclusion
Partial page navigation is a great feature of SharePoint that makes the user experience faster and more seamless! SPFx is a great programming model! However, combined, the two features make solid enterprise grade coding a must! SPFx services can stick around longer than you might expect, which can lead to unexpected behavior. Your ’little SPFx extension’ may impact data and other people in your org in a way that you did not think of when you published your SPPKG package! Always be aware of this when working with SPFx and make sure to take partial page navigation into account when building your customizations!
Happy coding! 🚀
Sources
spfx sharepoint
More
More blogs
Extending Microsoft 365 with custom retention controls - Part 2
New release of a small Microsoft 365 extension I've developed to view & manage retention controls.
Read more
Extending Microsoft 365 with custom retention controls
Thinking about a Purview post by Joanne C Klein, I've developed a small Microsoft 365 extension to view & manage retention controls.
Read more
Debugging production code in SPFx
A way to debug minified SPFx code in production against your original typescript code.
Read moreThanks
Thanks for reading

Thanks for reading my blog, I hope you got what you came for. Blogs of others have been super important during my work. This site is me returning the favor. If you read anything you do not understand because I failed to clarify it enough, please drop me a post using my socials.
Warm regards,
Martin
Microsoft MVP | Microsoft 365 Architect